关于树的种种
决策树是一种经典的监督学习思想,从它朴素的概念出发,衍生出了一系列模型和算法。因为概念太多,久而久之,我们变得只知其然而不知其所以然。作为一个有追求的调包侠,我在这里不成体系地提一些关于树的琐碎想法,谨作我个人的备忘。
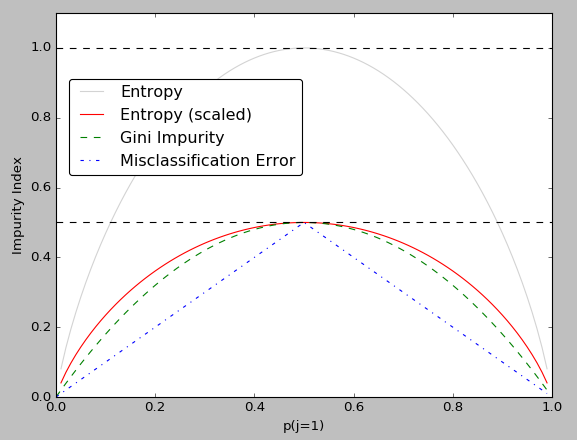
说到决策树算法,人们言必称ID3,C4.5和CART。ID3和C4.5的分裂原则(splitting criteria)都是基于entropy,而CART则是基于Gini impurity。C4.5和ID3最大的区别在哪里?ID3的分裂基于信息增益(information gain),这种方法最大的问题是倾向于选择值域广的特征(例如信用卡号这种对每个用户是唯一的特征永远会制造最大的信息增益)。 C4.5在信息增益的基础上考虑了特征本身的取值广度,采用信息增益率(information gain ratio)来惩罚值域较广的特征,从而避免过拟合。CART与前二者差异更大一点,因为它只使用二叉树(binary tree),这进一步避免了特征值域过广的问题,同时大大降低了模型的复杂度。CART使用的Gini impurity的p*(1-p)的形式,可以直接理解成从样本里随机拿两个样本且它们类别不一样的概率,因此其结果越小则数据纯度越高。实际上Gini impurity和entropy极其相似,但Gini impurity避免了entropy计算中的对数运算,因此提高了算法的效率。下面是关于二者相似性的一点验证:
{kind=link}
方便起见,这里记以2为底的对数函数为lg。
Entropy: p * (-lg(p))
Gini: p * (1-p)
可以看到上面两个式子的第一部分都是一样的,我们只需要探究(-lg(p))和(1-p)的相似性即可。
将f(x) = -lg(x)在x0处进行泰勒一阶展开:
f(x0) = f(x0) + f'(x0) * (x - x0) = -lg(x0) - 1/x * (x - x0)
当x0为1时,上式为(1-x)
当x0为0.5时,上式为2*(1-x)
由上述推导可知,Entropy在1/2时大约是Gini的两倍,而在1时二者基本相等,将两个函数画出来就可以看到这种关系的存在。
{kind=link}
决策树在实际应用中较少以单棵树的形式出现,一方面不加以剪枝的决策树极易过拟合,而剪枝后的单棵树往往精度感人(weak learner),但也正因为其对参数(比如树的深度)和数据(不同样本或特征)的敏感性,恰恰非常适合拿来与集成学习(ensemble learning)搭配使用。
集成学习,主要有Boosting和Bagging(Bootstrap aggregating)两种思想。Boosting对训练集进行多轮训练,每一轮都对前一轮分类错的样本加强权重,最后将多个分类器按performance组合起来,比较有代表性的算法是AdaBoost。Bagging同样是对训练集训练多个分类器,但各个分类器之间几乎独立,甚至为了增加独立性,可以在每次训练时对样本和特征进行抽样,最后同样也是综合所有分类器,最具代表性的算法是Random Forest。
Boosting和bagging代表了两种思路,Boosting意在通过不断的优化来减少分类器的bias,而bagging意在通过增加独立的分类器数量来减少variance。理论上,boosting会随着iteration的增加而产生过拟合,但事实上人们发现即使training error不再下降,testing error依旧会随着iteration的增加而下降。对此,AdaBoost的作者给出了一种解释,基本上就是说margin (sample distance to decision boundary)依旧会随着iteration的增加而不断被改善。这个问题后来还有很多讨论,此处不做赘述。
Boosting是一种应用广泛的思想,除却AdaBoost中每个iteration更新权重的做法,另一种在regression tree中常用的方式是每个iteration计算预测的残差,然后下个iteration试图去预测上一个iteration的残差。当然,这里的残差是一种特殊情况,我们本质上的目标是最小化loss function,特别是当loss function中包含正则项时,一种更泛化的做法是找到loss function的gradient,然后在每个iteration不断预测上个iteration的gradient,当我们采用平方损失时,这个gradient就恰好是残差这种特例。这个算法就是经典的GBDT(Gradient Boosting Decision Tree)。
现在我们来看GBDT,纵然曾一度称雄各种比赛,它是否还有改进空间?当然是有的。Tianqi Chen在2016年发布的XGBoost就是GBDT的全方位提升版。XGBoost有哪些改进?主要有以下几方面:
-
改进目标函数,在原本的loss function的基础上加上了正则项来惩罚叶节点的个数和取值,从而降低过拟合的风险
-
采用目标函数的二阶泰勒展开作为优化目标,显然,相对于GBDT的一阶gradient,二阶泰勒展开会更加精确
-
不同于传统CART的分裂方式,XGBoost重新定义了一种用于寻找分割点的收益函数,同时为了节省所需的计算,提出了一种基于特征值分位数的近似算法
-
提出了一种解决特征值missing value的做法,不同于直接忽略missing value,XGBoost尝试将它们分别划分到左右分支并根据收益函数决定最终划分的方向
-
在实现方面,将数据根据特征的排序信息存储到块结构中,以方便在选择最优分裂时对不同特征进行并行计算(当然,boosting的iteration还是依赖串行)
以上就是我关于树的种种琐碎想法。作为经典的算法,我个人常常用相关模型来做我的baseline,而其优美的结构和ensemble的思想则极具延展性,在更广的应用领域里不断创造新的价值。
参考文献: