从Embedding说起
Embedding的本质是将文本映射到向量空间,从而便于我们对其进行分析和建模。如何完成向量化?最偷懒的做法是one-hot encoding,一个萝卜一个坑。然而这种做法存在很多问题,比如,在词数量较多的时候向量的维数会非常高,又比如,这种做法不具备描述词与词之间关系(同义词)的能力。因此,我们需要一些更高级的办法。
在word embedding的发展过程中,曾出现过两种思路:基于频率(frequency based)和基于预测(prediction based)。
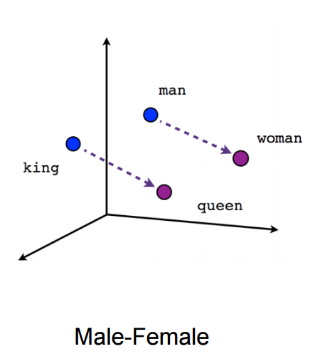
基于频率的方法,顾名思义,它考虑词汇在语料中出现的次数。比如tf–idf就是一个基于频率的衡量词汇和文本关联性的经典指标。比较著名的基于频率的word embedding算法是LSA,它通过构建共现矩阵(co-occurrence matrix)并对其进行奇异值分解(SVD)来获取维数较低的词向量。LSA的逻辑相当清晰,但也存在明显的缺点:1.共现矩阵会消耗较大的memory,同时SVD在计算上复杂度较高;2.基于共现产生的词向量在word analogy上表现欠佳,往往得不到king - man + woman = queen这样intuitive的结果。
{kind=link}
这里插一句,我个人对word analogy是否具有人们所标榜那样的重要意义表示怀疑。对我来说embedding的好坏最终还是取决于模型的表现,词向量过于专注本身的优美特性(何况analogy是否应该作为唯一的标准?)也许是一种本末倒置。我并不是唯一一个有这种想法的人,也有团队提出过线性关系未必是衡量word analogy的唯一标准,究竟孰是孰非,交由大家判断。
回到正题,另一种word embedding的思路是基于预测的方法,最具代表性的就是谷歌在2013提出的Word2Vec。和LSA这种基于全局共现矩阵的算法不同,Word2Vec用一个滑动的窗口遍历整个数据集,基于每一个局部窗口内的数据来预测上下文(Skip-gram)或预测缺失值(CBOW)。预测模型是一个有一层hidden layer的神经网络,我们将每一个one-hot encoding后的词(如果一共有N个词的话,每个词有N维)通过一个系数矩阵映射到hidden layer上(每个词有m维,m是我们期望得到的词向量的维数),再用一个系数矩阵将hidden layer映射到输出层(每个词又变成N维,因为要包含所有可能的预测选项),并用softmax给出每一个预测选项的概率。接下来就是常规套路,计算loss并通过gradient descent不断更新系数矩阵。最后,我们期盼的词向量就是模型训练完后的系数矩阵。
以上所述的Word2Vec的训练过程是比较低效的,每一轮训练的loss是N维的,也就是说原则上每一轮都要对所有词的系数进行一次更新。但事实上每一轮只有一个词是正确的预测结果,除了正确结果外其它词的loss是比较小的,为了一个很小的loss犯不着把整个反向传播都走一遍。为了提高效率,人们提出了一些小技巧,比如用Negative sampling来减少每一轮训练需要更新的weight数量,或者使用Hierarchical softmax来优化输出结构。
Word2Vec当然也有缺点,不同于基于全局共现矩阵的LSA算法,其基于局部滑窗的训练方式没有利用好语料在全局的分布信息。为此,斯坦福的团队在2014年提出了GloVe。GloVe在我看来兼顾了上述两种思路的优点,从共现矩阵出发,基于词相关性的性质,构建了共现矩阵(X)关于词向量(W)的关系(Wi*Wk + bi + bk = log(Xik)),以此计算loss并训练词向量。这个关系的推导非常飘逸(当然也很intuitive),直接从”我希望词向量具有怎样的性质(analogy)“出发,拼凑出了一个函数形式,详情可以直接参考原论文。
到这里,关于词向量的讨论其实已经接近尾声,我们建立了每个单词到向量空间的映射,且向量一定程度上可以反映词义。然而,单词到向量映射这个概念本身就存在缺陷:它不能反映一词多义。这注定了以此为基础构建的模型无法真正像人一样去解读文本在不同上下文中的不同含义。
跳出词向量的局限性,人们开始关注sequence本身,2017年,谷歌提出了Transformer的概念,其基于self-attention和encoder/decoder结构的方法对后来的模型产生了深远影响。什么是self-attention?一言以蔽之,就是对文本中的每个词,联系上下文(向量点积求相似度),从而产生(softmax)一个包含更多信息的增强语义输出。Attention function由Query,Key和Value三个参数矩阵构成:Attention(Q,K,V) = softmax(Q*K/sqrt(d))V,细节可以参考Jay的这篇科普文。谷歌那篇论文中的Transformer结构使用了六层encoder和六层decoder,每个encoder包含一个self-Attention层和一个feed forward层,每个self-attention都使用8个头的multi-headed attention(8组Q,K,V矩阵),其训练成本巨大,但好在multi-headed不同head之间是不相关的,因此可以并行计算,加快了训练速度。
Transformer声名大噪,其实部分要归功于2018年谷歌的另一篇论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding。BERT的出现彻底改变了NLP的格局,在其后的时间里它几乎横扫了各大比赛,而BERT的encoding方式正是Transformer。该论文发现Transformer较BiLSTM更为灵活,对信息的获取能力更强(毕竟不再受方向的限制)。BERT的另一个特点是使用了Masked LM和Next Sentence Prediction (NSP)的预训练方法,当然,考虑到BERT惊人的深度和复杂度,谷歌的TPU可能才是BERT得以成功的另一个重要原因。
NLP在未来毫无疑问依旧是最热门的领域之一,但我觉得NLP中的思想,特别是对sequence的处理方式,在其他领域,或面对不同类型的数据时,应该具有很大的发展潜力,以后有机会也许可以继续探讨。
参考文献: